이전 포스팅에서 유통 데이터에 대한 소개와 전처리를 진행했습니다. 이번 포스팅에서는 본격적인 분석에 들어가겠습니다.
분석 목적을 다시 한번 정리해 보면 다음과 같습니다.
- 시간의 흐름에 따라 매출, 주문 고객수, 주문 단가의 추이는 어떻게 달라지는가?
- 리텐션 분석: 시간의 흐름에 따라 고객이 얼마나 남고 이탈했는가?
- RFM 분석 : 고객 행동에 따라 고객을 유형화하기
해당 페이지에서 다룰 내용은 분석 목적 1번입니다.
4. 시간의 흐름에 따른 추이 분석
① 시간의 흐름에 따라 매출 추이는 어떻게 달라지는가?
매출 추이를 알아보기 전에 전처리가 완료된 데이터를 다시 살펴보겠습니다.

- InvoiceNo : 영수증 번호
- StockCode: 상품 번호
- Description: 상품명
- Quantity: 판매 수량
- InvoiceDate: 결제 날짜
- UnitPrice: 개당 가격
- CustomerID: 고객 번호
- Country: 나라
- date_ymd: 결제 연월일
- year: 결제 연도
- amount: 매출
매출 추이를 구하기 위해선 일자별 총매출에 대한 정보가 필요합니다.
일자별 총매출은 date_ymd에 해당하는 총 amount를 구하면 됩니다.
gropby 함수를 통해 해당 내용을 생성해 줍니다.
amount_by_date = data.groupby('date_ymd')['amount'].sum().reset_index() # 일자별 총매출
amount_by_date
fig= px.line(data_frame= amount_by_date, x = 'date_ymd', y = 'amount')
fig.show()시간의 흐름에 따라 매출 추이를 시각화해 본 결과, 시간이 흐르면서 매출 규모가 약간 우상향 하는 것처럼 보입니다.
특히 마지막 날인 2011년 12월 9일에 피크를 찍은 것을 확인할 수 있습니다.
② 시간의 흐름에 따라 주문고객수 추이는 어떻게 달라지는가?
이제 주문고객에 대해 알아보겠습니다.
이번에도 마찬가지로 groupby 함수를 이용해 일자별 주문고객수를 구할 수 있습니다.
여기서 주의해야 할 점은 CustomerID의 경우 고유값이기 때문에 sum을 하는 것이 아닌 nunique 함수를 사용해야 되다는 것입니다.
customer_count_by_date = data.groupby('date_ymd')['CustomerID'].nunique().reset_index() # 일자별 주문 고객수
customer_count_by_date
생성한 customer_count_by_date를 출력해 보면 컬렴명이 date_ymd, CustomerID입니다. 여기서 CustomerID 보단 고객 수 이기 때문에 rename을 해줄 필요가 있습니다.
customer_count_by_date = customer_count_by_date.rename({'CustomerID' : 'customer_count'}, axis=1)
customer_count_by_date
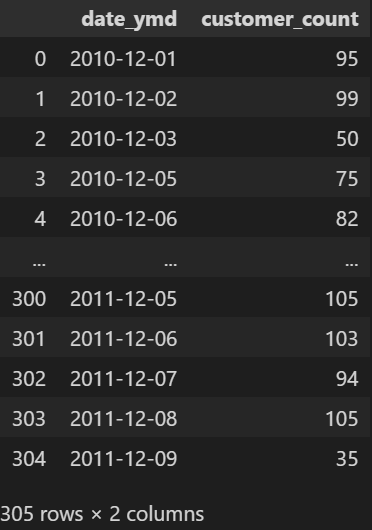
fig = px.line(data_frame= customer_count_by_date, x = 'date_ymd', y = 'customer_count')
fig.show()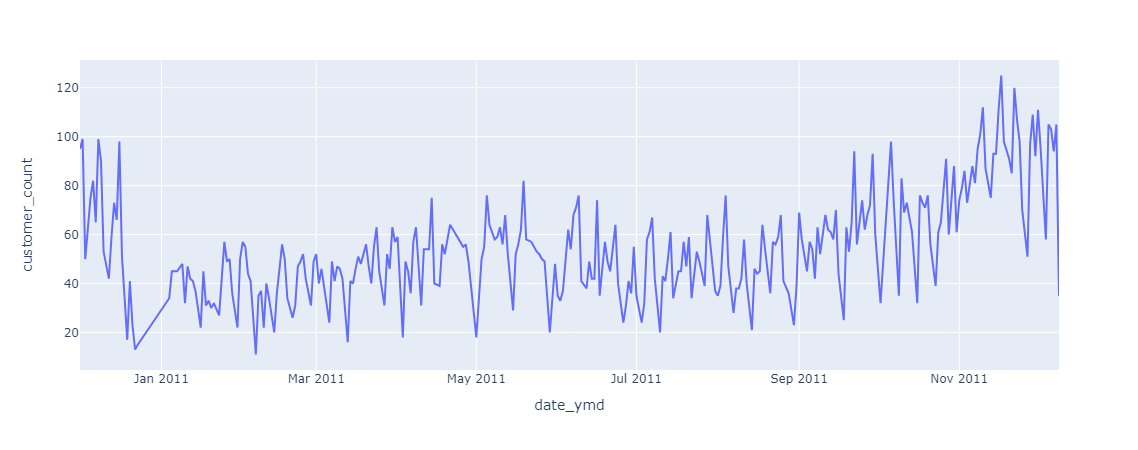
시각화 결과, 시간의 흐름에 따라 주문 고객수는 우상향 하는 경향으로 보입니다.
③ 시간의 흐름에 따라 주문단가 추이는 어떻게 달라지는가?
이번엔 주문단가에 대해 알아보겠습니다.
주문단가를 구하기 위해선 일자별 총매출과 일자별 총 주문건수에 대한 정보가 필요합니다.
일자별 총매출의 경우 ①에서 구한 amount_by_date입니다.
그럼 일자별 총 주문건수는 어떻게 구할 수 있을까요?
바로 영수증번호를 나타내는 InvoiceNo변수를 이용하면 구할 수 있습니다.
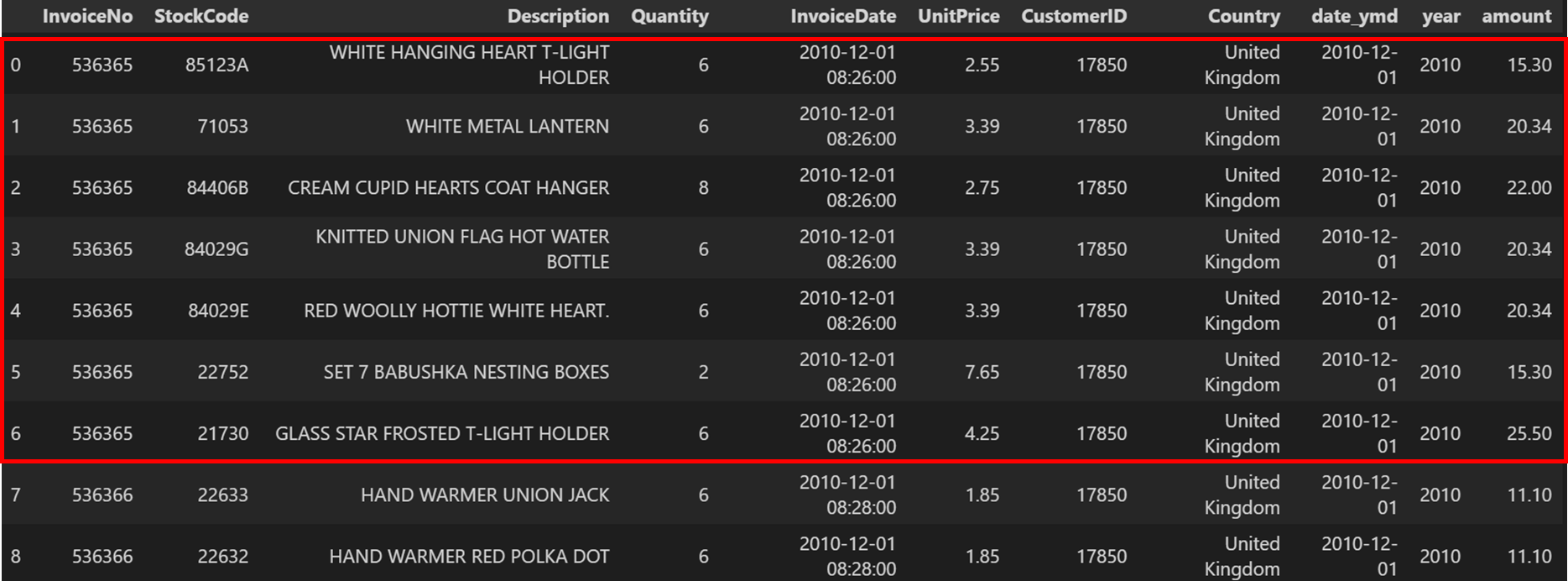
데이터셋을 다시 한번 살펴보겠습니다.
고객번호가 17850인 사람이 동일한 영수증번호 536365를 부여받으면서 상품을 구매했다는 내용이 들어있습니다.
그렇기 때문에 일지별 유니크한 InvoiceNo를 구하면 일자별 총 주문건수에 대한 내용이 됩니다.
incoive_count_by_date = data.groupby('date_ymd')['InvoiceNo'].nunique().reset_index().rename({'InvoiceNo' : 'invoice_count'}, axis= 1) #일자별 총 주문수
incoive_count_by_date.head()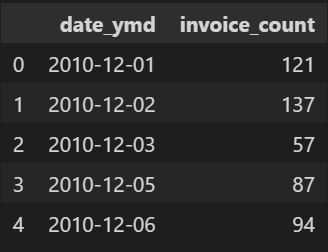
이제 주문단가를 구해보겠습니다.
주문단가는 일자별 총매출 / 일자별 총 주문 건수로 구할 수 있습니다.
앞서 구한 일자별 총매출과 일자별 총 주문건수에 대해 merge 함수를 통해 데이터프레임을 생성해 줍니다.
invoice_amount = pd.merge(amount_by_date, incoive_count_by_date, on = 'date_ymd')
invoice_amount
amount_per_invoice라는 주문단가 변수를 생성해 줍니다.
invoice_amount['amount_per_invoice'] = invoice_amount['amount'] / invoice_amount['invoice_count'] #주문단가
invoice_amount.head()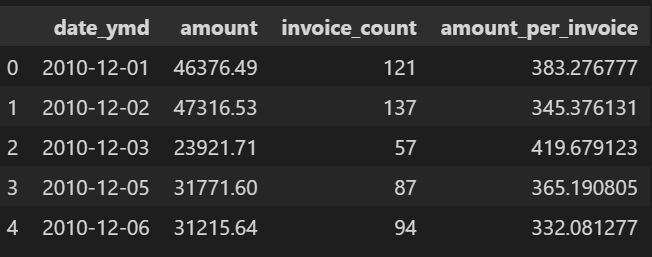
fig = px.line(data_frame= invoice_amount, x = 'date_ymd', y = 'amount_per_invoice')
fig.show()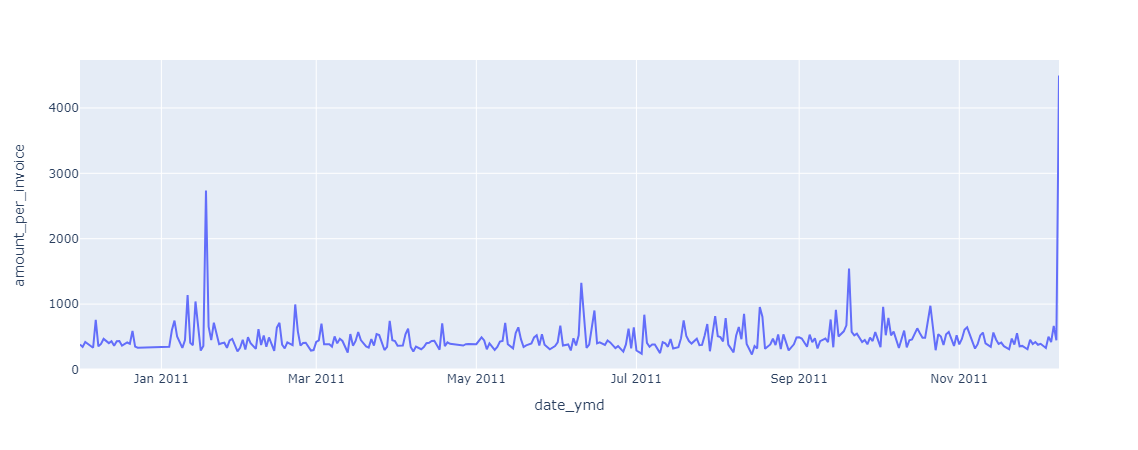
주문단가를 시각화한 결과, 비교적 일정하게 유지된 것을 확인할 수 있습니다.
다만 데이터의 마지막날인 2011-12-09에만 피크 친 것으로 보아, 주문 단가가 높은 상품이 있었을 것이라 추정됩니다.
나머지 분석은 다음 포스팅으로 찾아뵙겠습니다. 감사합니다.
'데이터 분석 > 프로젝트' 카테고리의 다른 글
| [Python] 유통 데이터를 활용한 리텐션과 RFM 분석(4) (0) | 2024.08.25 |
|---|---|
| [Python] 유통 데이터를 활용한 리텐션과 RFM 분석(3) (0) | 2024.08.01 |
| [Python] 유통 데이터를 활용한 리텐션과 RFM 분석(1) (0) | 2024.07.21 |
| [마케팅 데이터 분석] AARRR 실습(1) - Acquisition (2) | 2023.09.09 |
| [논문] Encoder Decoder 알고리즘을 이용한 시계열 자료 예측 (1) | 2022.08.11 |



