
데이터 분석을 하시는 분들이라면 AARRR에 대해 많이들 알고 계실 거라 생각합니다.
특히 DA를 희망하시는 분들이라면 채용공고에 자격 요건으로도 한 번씩 보셨을 거 같은데요.
저 또한 대략적인 개념은 알고 있지만 전체적인 내용에 대한 정리가 필요하다 판단하여 해당 글을 작성합니다.
실습 내용은 패스트캠퍼스의 직장인을 위한 파이썬 데이터분석 올인원 패키지를 참고하였습니다.
1. 데이터 설명 및 문제 정의
분석에 사용한 데이터는 캐글에 있는 미디어별 광고비와 매출 데이터입니다.
(https://www.kaggle.com/datasets/sazid28/advertising.csv)
- TV: TV 매체비
- radio: 라디오 매체비
- newspaper : 신문 매체비
- sales: 매출액
우선 분석을 하기전 정리해야 하는 부분 몇 가지가 있습니다.
실제로는 광고 매체비 이외의 많은 요인이 매출에 영향을 미칠 것입니다. (e.g. 영업인력 수, 경기, 유행 등)
하지만 이 분석에서는 다른 요인들은 모두 동일할 때, 매체비만 변했을 때 매출액의 차이가 발생한 것이라 간주하고 분석을 진행했습니다.
또한 Acquisition 단계의 경우 사용자를 우리 서비스로 데려오는 것과 관련된 활동을 의미하기 때문에
실제 종속변수가 매출액이기 보다는 방문자수, 가입자수, DAU, MAU 등의 지표와 더 관계가 있을 것입니다.
하지만 실제 상황과 맞는 데이터를 구하기 어려워 해당 데이터를 사용하여 분석했다는 점 양해 부탁드립니다.
추가로, 해당 데이터의 경우 newspaper를 주 미디어로 잡고 있습니다. 이를 통해 예전 데이터라 생각할 수 있습니다.
그렇기 때문에 분석 시점을 2011년이라 가정했습니다.
2. 분석 목적
그럼 분석 목적에 대해 설명드리겠습니다.
분석의 목적은 총 3가지 입니다.
✔️ 각 미디어별로 매체비를 어떻게 쓰느냐에 따라 매출액이 어떻게 달라질지 예측하기
✔️ 궁극적으로 매출액을 최대화할 수 있는 미디어 믹스 구성 도출하기
✔️ 이 미디어믹스는 향후 미디어 플랜을 수립할 때 사용 가능
3. 데이터 EDA
본격적인 EDA를 시작해 보겠습니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 데이터 불러오기
df = pd.read_csv('Advertising.csv')
print(df.shape) #(200,4)
df.head(5)
데이터는 총 4개의 컬럼과 200개의 행으로 구성되어 있습니다.
# 변수간의 관계 확인
corr = df.corr()
sns.heatmap(corr, annot= True)
변수 간의 관계를 보면 TV와 매출은 0.78로 높은 상관이 있어 보이는 반면 newspaper의 경우 0.23으로 관계가 낮아 보입니다.
# 변수간 산점도
sns.pairplot(data = df[['TV','radio', 'newspaper', 'sales']])
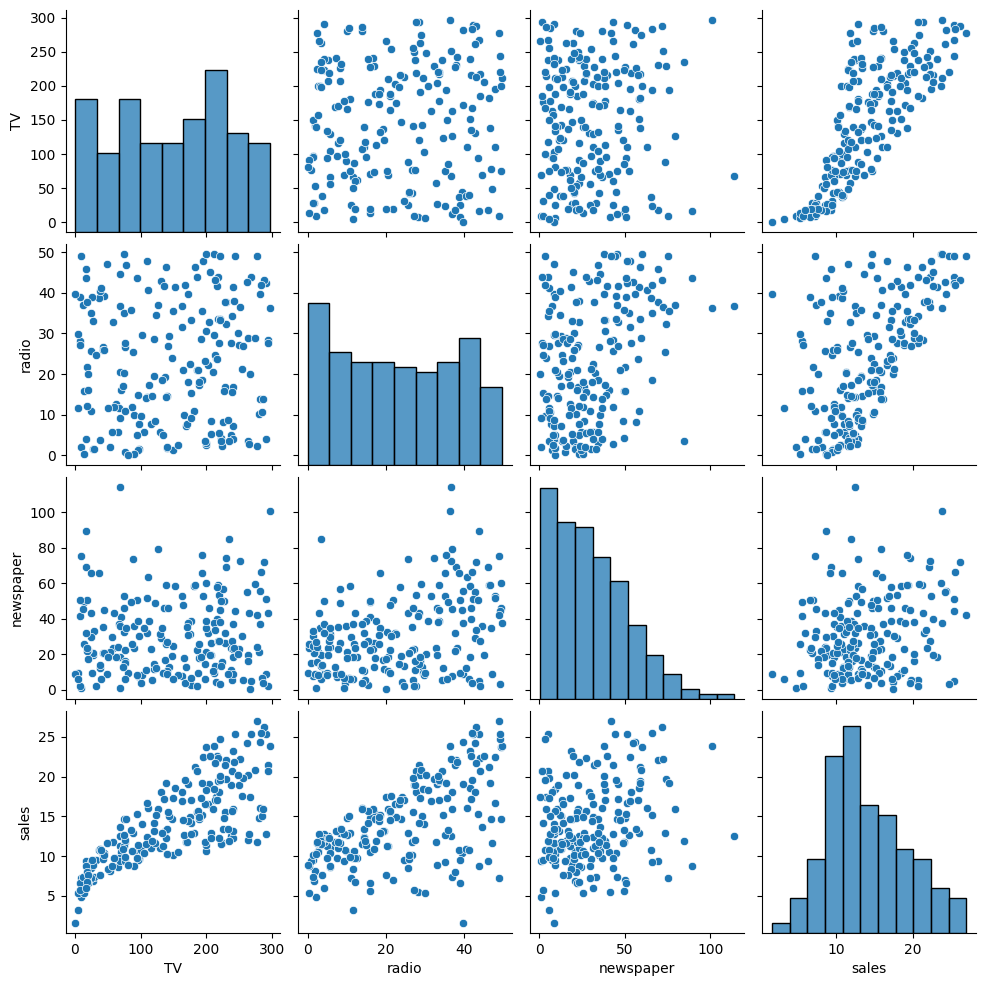
각 변수끼리의 산점도를 그려봤을 때 TV와 매출은 거의 선형을 띄고, 라디오와 매출도 어느 정도 관계가 있어 보입니다.
다만 신문의 경우 산점도를 통해 관계를 파악하는 것은 어려워 보입니다.
4. 분석 모델링: 매체비로 세일즈 예측하기
매출액을 최대화할 수 있는 미디어 믹스 구성 도출을 위해 선형 회귀 분석을 진행해 보겠습니다,
# 선형회귀 분석
import statsmodels.formula.api as sm
model1 = sm.ols(formula = 'sales ~ TV + radio + newspaper', data = df).fit()
print(model1.summary())
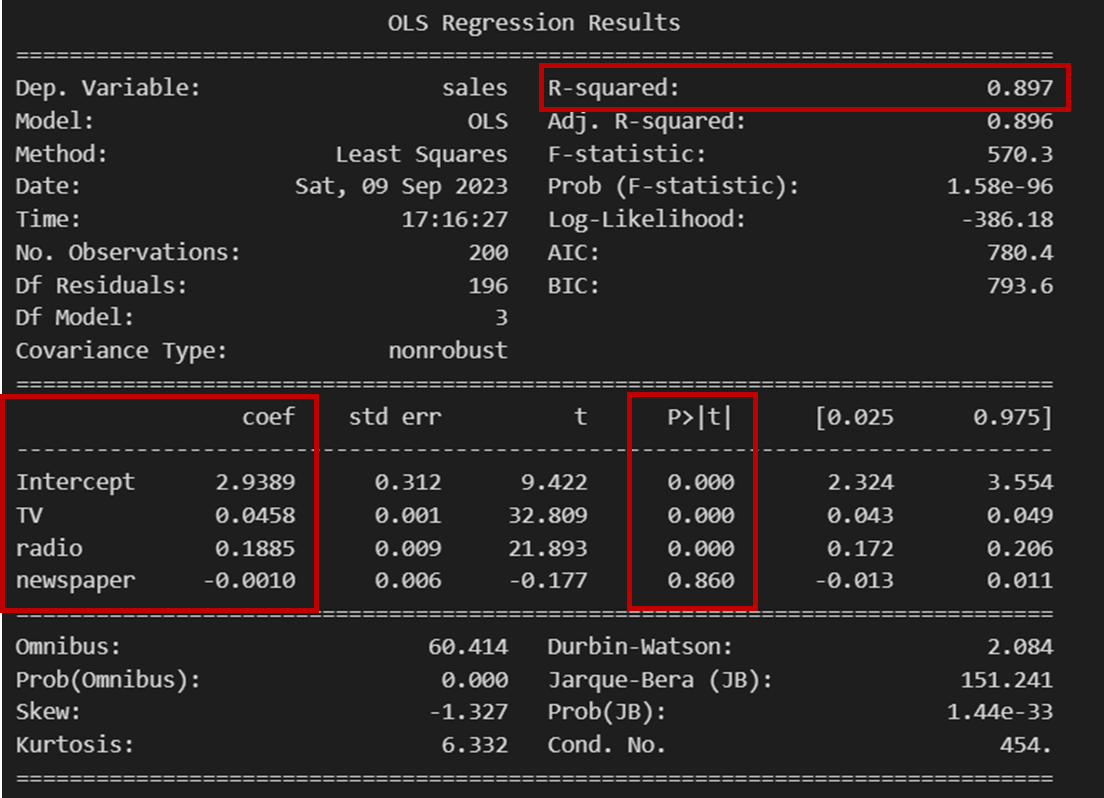
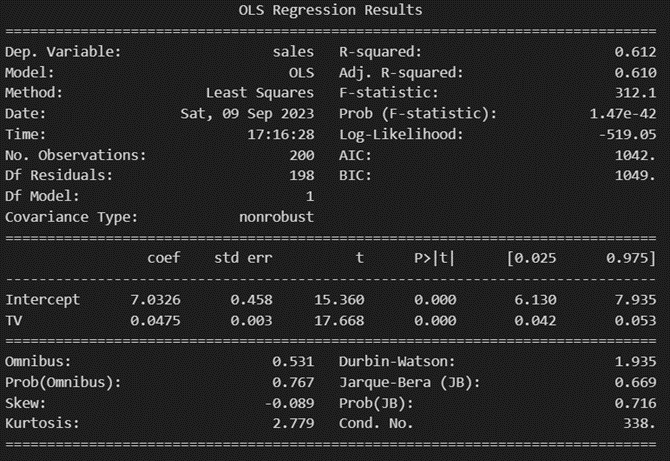
회귀분석 결과를 출력해 보면 다음과 같은 결과물이 나옵니다.
회귀분석 결과 해석이 어렵다 하시는 분들은 빨간색으로 표시된 부분을 집중해서 봐주세요.
우선 첫 번째로 봐야 하는 부분은 결정계수인 R-squared입니다.
결정계수는 추정된 모형에서 독립변수 x가 종속변수 y를 몇 퍼센트 정도 설명한다는 의미를 지닙니다.
여기서는 결정계수가 0.897이니까 3개의 독립변수가 종속변수의 약 90%를 설명한다고 할 수 있겠네요.
(몇 퍼센트 이상이어야 실질적으로 유용하다 하기는 어렵지만 실제 분석에서 이렇게 높은 경우는 거의 없다고 보시면 됩니다.
이렇게 높게 나온 경우 독립변수와 종속변수 간의 연관이 있을 경우가 높을 것입니다. → 회귀분석 가정 위배)
두 번째로 봐야 할 것은 p-value(유의확률)입니다. 출력된 결과물에서는 p>|t| 부분을 보시면 됩니다.
p-value에 대한 자세한 설명은 생략하겠습니다.
간단하게만 말하면 유의 수준 0.05에서 봤을 때, p-value의 값이 그것보다 작으면 통계적으로 유의하다, 0.05보다 크면 통계적으로 유의하지 않다고 판단합니다.
이제 변수별 p-value를 보면 TV나 radio의 경우 유의확률이 0.00 수준으로 매우 작아 유의하지만,
newspaper의 경우 0.86으로 유의하지 않다는 것을 알 수 있습니다.
즉, 신문 광고가 매출액에 미치는 영향은 유의하다고 보기 어렵습니다.
마지막으로 봐야 될 부분은 coef(회귀계수)입니다.
회귀분석을 수행하여 나온 회귀계수를 통해 하나의 식을 생성할 수 있습니다.
해당 분석에서 나온 회귀식은 sales = 2.9389 + 0.0458 * TV + 0.1885 * radio - 0.0010 * newspaper 네요!
분석 결과에서 newspaper가 유의하지 않다고 나왔으니,
3개의 독립변수를 전부 사용한 모델에서부터 하나씩 변수를 제거하는 회귀 분석을 수행해 보겠습니다.
# 변수의 포함 여부에 따른 ols 결과 파악
model1 = sm.ols(formula = 'sales ~ TV + radio + newspaper', data = df).fit()
model2 = sm.ols(formula = 'sales ~ TV + radio', data = df).fit()
model3 = sm.ols(formula = 'sales ~ TV ', data = df).fit()
print(model1.summary())
print(model2.summary())
print(model3.summary())
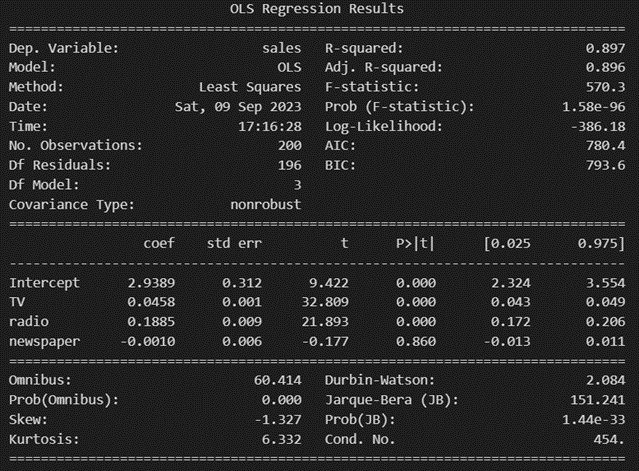
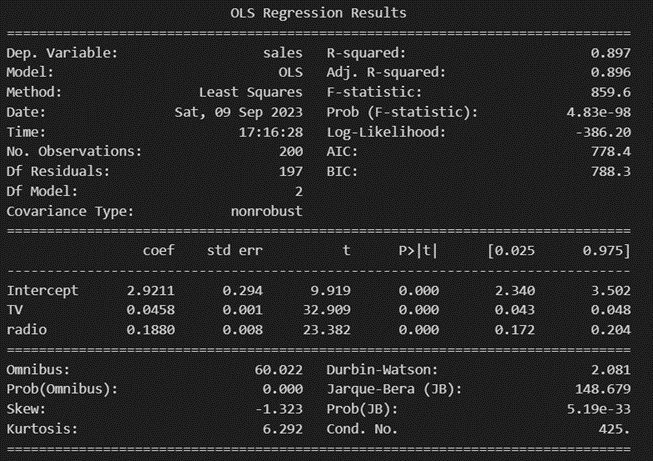
선형 회귀 분석에서 최적의 모델을 선택할 때 가장 쉬운 방법은 AIC, BIC가 가장 낮은 모형은 어떤 것인지 파악하는 것입니다.
(물론 AIC, BIC가 유일한 판단 기준은 아니고 다른 기준들과 함께 고려된다 합니다)
해당 기준으로 model1부터 model3까지 비교해 봤을 때, newspaper를 제거한 model2의 AIC, BIC가 가장 낮은 걸 확인할 수 있습니다.
또한 회귀분석에서 결정계수는 독립변수의 유의미함과 무관하게 독립변수의 수가 증가하면 결정계수 값도 커진다는 성질이 있습니다.
이를 고려해 봤을 때, 3개의 매체를 이용한 model1과 2개의 매체를 이용한 model2의 결정계수가 동일한 것을 보면 newspaper를 제거한 것이 더욱 효과적인 마케팅 방법이라 할 수 있을 거 같습니다.
지금까지의 분석을 통해 매출액을 최대화할 수 있는 미디어 믹스 구성은 앞으로는 신문 광고를 하지 않고 TV, radio 광고에 집중하는 것이라는 결론을 도출할 수 있습니다.
첫 번째 분석 목표였던 각 미디어별 매체비에 따른 매출 예측은 다음과 같은 방법을 통해 할 수 있습니다.
# 각 미디어별 매체비에 따른 sales를 예측
model1.predict({'TV': 300, 'radio': 10, 'newspaper': 4}) # sales 예측 금액
# 18.549433
model1에서 얻은 회귀식은 sales = 2.9389 + 0.0458 * TV + 0.1885 * radio - 0.0010 * newspaper입니다.
여기서 TV에 300, radio에 10, newspaper에 4를 대입하면 매출의 예측 금액을 알 수 있습니다.
5. 추가 검정
위의 분석 결과에서 신문광고가 유의미하지 않다고 나왔지만 데이터에 문제가 없는지에 대한 확인이 필요합니다.
이를 위해 데이터의 분포를 파악해 보겠습니다.
# 데이터 분포 시각화
# 3개의 시각화를 한 화면에 배치
figure, ((ax1, ax2, ax3)) = plt.subplots(nrows = 1, ncols = 3)
# 시각화의 사이즈 설정
figure.set_size_inches(20,6)
# 미디어별 매체비 분포를 sns.distplot으로 시각화
sns.distplot(df['TV'], ax = ax1)
sns.distplot(df['radio'], ax = ax2)
sns.distplot(df['newspaper'], ax = ax3)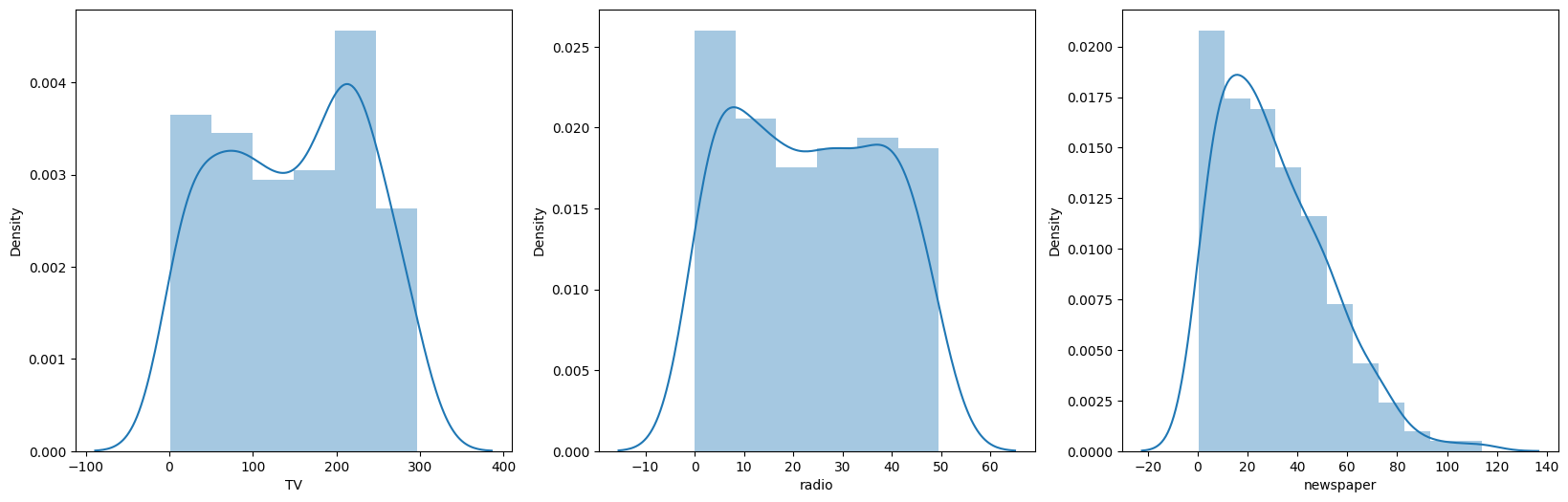
TV, radio의 경우 정규분포라고 보긴 어렵지만 그래도 중앙에 분포되어 있는 걸 확인할 수 있습니다.
반면, newspaper의 경우 한쪽으로 치우쳐진 분포라 분포에 대한 처리가 필요해 보입니다.
이를 위해 로그 변환을 진행해 줬습니다.
# 정규화를 위해 로그 변환
df['log_newspaper'] = np.log(df['newspaper'] + 1) # 숫자 1을 더해주는 이유는 로그함수가 0이 되면 음의 무한대 값으로 가기때문에
df[['log_newspaper', 'newspaper']]
변환된 결과를 다시 시각화해 봅시다.
# 변환된 결과를 재 시각화
# 4개의 시각화를 한 화면에 배치
figure, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows = 2, ncols = 2)
# 시각화의 사이즈 설정
figure.set_size_inches(20,10)
# 미디어별 매체비 분포를 sns.distplot으로 시각화
sns.distplot(df['TV'], ax = ax1)
sns.distplot(df['radio'], ax = ax2)
sns.distplot(df['newspaper'], ax = ax3)
sns.distplot(df['log_newspaper'], ax = ax4)
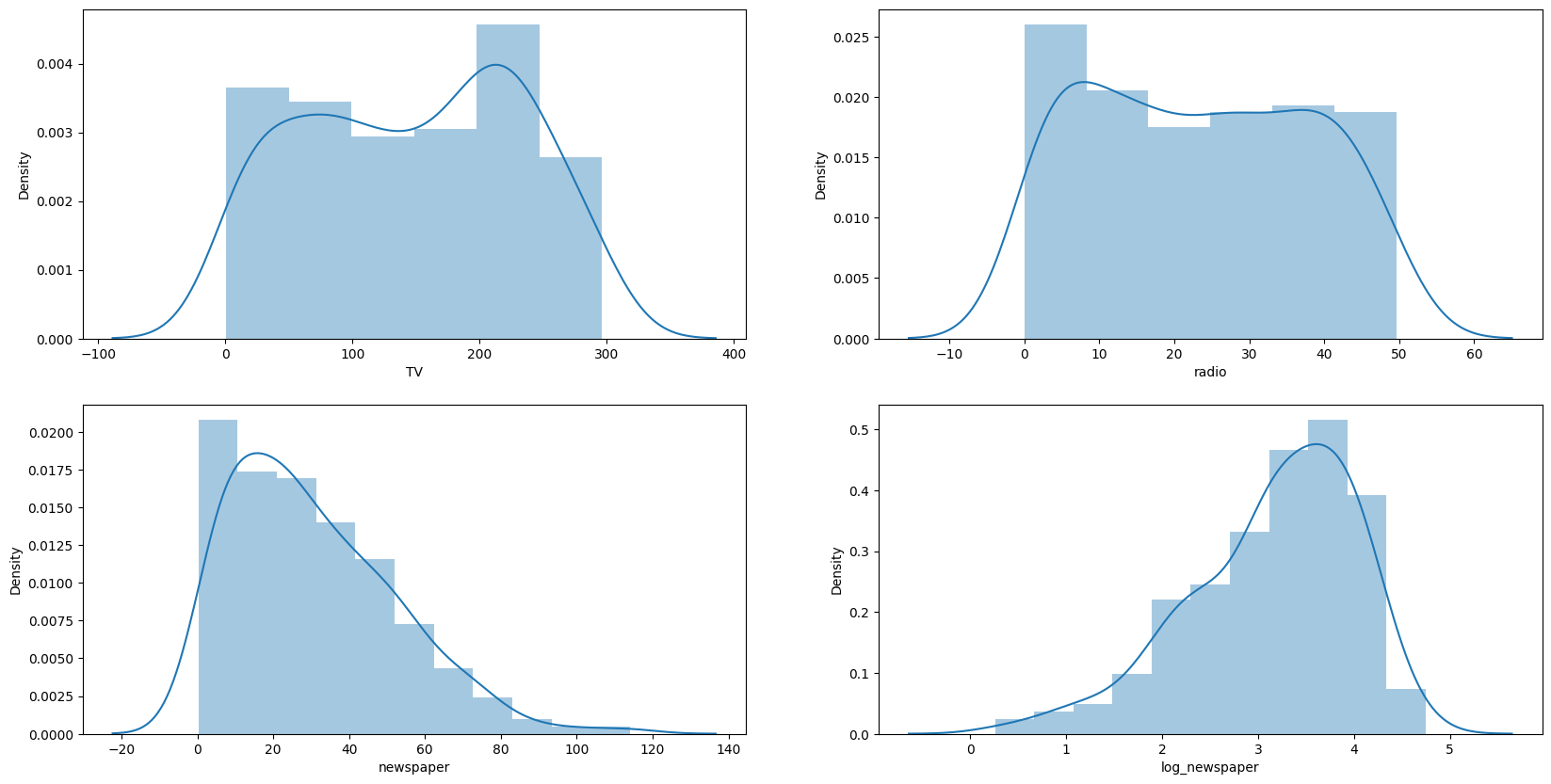
이제 변환된 log_newspaper를 통해 회귀분석을 수행해 봅시다.
# 변환한 newspaper 변수 결과도 포함하여 ols 분석 결과 확인
model1 = sm.ols(formula = 'sales ~ TV + radio + newspaper', data = df).fit()
model4 = sm.ols(formula='sales ~ TV + radio + log_newspaper', data = df).fit()
print(model1.summary())
#print('---')
print(model4.summary())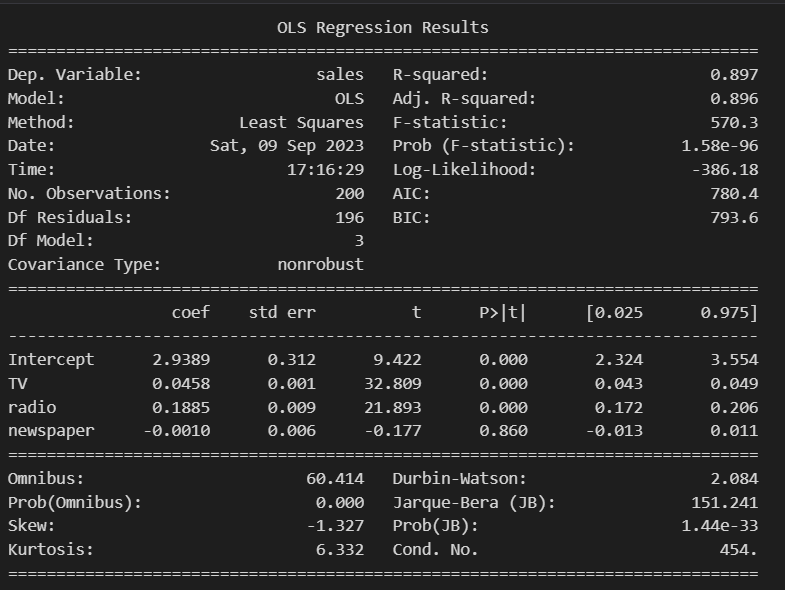
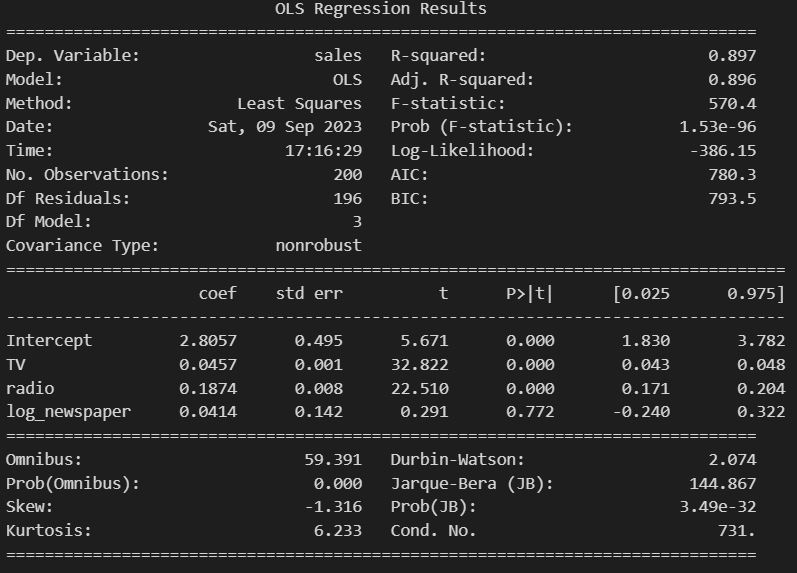
model1과 model4의 결과를 비교해 보면 newspaper의 계수의 부호가 바뀐 것을 확인할 수 있습니다. (-0.0010 → 0.0414)
그러나 log 변환을 통해 정규화를 진행해도, log_newspaper의 유의확률은 아직도 유의 수준보다 큰 걸 확인할 수 있습니다.
즉, 해당 분석을 통해 데이터를 정규화해도 신문이 매출에 미치는 영향이 통계적으로 유의하다 보기 어려우며, 신문광고가 매출에 미치는 영향이 크지 않다고 해석할 수 있습니다.
6. 분석 결과 해석 적용 방안
앞서 설정한 분석 목적은 다음과 같습니다.
- 각 미디어별로 매체비를 어떻게 쓰느냐에 따라 매출액이 어떻게 달라질지 예측하기
- 궁극적으로 매출액을 최대화할 수 있는 미디어 믹스 구성 도출하기
- 이 미디어믹스는 향후 미디어 플랜을 수립할 때 사용 가능
데이터 분석을 통해 도출한 결과를 정리하면,
1) 매출액 예측 → model.predict을 통해 해결
2,3) 매출액 최대화를 위한 미디어 믹스 구성 방안 및 향후 플랜
- 현재 TV, radio, newspaper 총 3가지 매체를 통한 광고를 진행하고 있지만, 분석 결과 신문 광고를 중단하고 TV, radio 광고 위주로 집행해야 한다는 결론.
- 또한 회귀분석 결과, 각 매체별 계수를 보면 TV 광고는 비용대비 효율이 라디오보다 떨어지는 것으로 보임. (model2의 계수가 각각 0.0458, 0.1880이므로) 그렇기 때문에 앞으로 라디오 광고를 효율적으로 하면 매출 상승에 긍정적인 영향을 끼칠 것.
이것으로 본 포스팅을 마치겠습니다.
'데이터 분석 > 프로젝트' 카테고리의 다른 글
| [Python] 유통 데이터를 활용한 리텐션과 RFM 분석(2) (0) | 2024.07.21 |
|---|---|
| [Python] 유통 데이터를 활용한 리텐션과 RFM 분석(1) (0) | 2024.07.21 |
| [논문] Encoder Decoder 알고리즘을 이용한 시계열 자료 예측 (1) | 2022.08.11 |
| [생존분석] R을 이용한 백혈병 환자 데이터 분석 (0) | 2022.08.10 |
| 위드(with)코로나 시대 소비 변화 - 번외 (0) | 2022.08.09 |



