이전 포스팅에서 크롤링을 통해 원하는 부동산 데이터를 수집했습니다. 이번 포스팅에서는 수집된 데이터를 이용해 최적의 자취방을 구해보겠습니다.
2. 조건 구체화
최적의 자취방을 구하기 위해 설정한 세부 조건은 다음과 같습니다.
✔️ 보증금 3000만 원 이하
✔️ 월세는 저렴할수록 좋음
✔️ 지하, 반지하, 꼭대기층은 선호하지 않음
✔️ 전용면적이 클수록 좋음
✔️ 북향은 선호하지 않음
✔️ 연식이 오래되지 않을수록 좋음
✔️ 지하철역에서 가까울수록 좋음
3. 데이터 전처리
분석을 진행하기 위해 전처리를 진행하겠습니다.
import pandas as pd
import numpy as np
data = pd.read_excel('부동산데이터.xlsx')
data.head(3)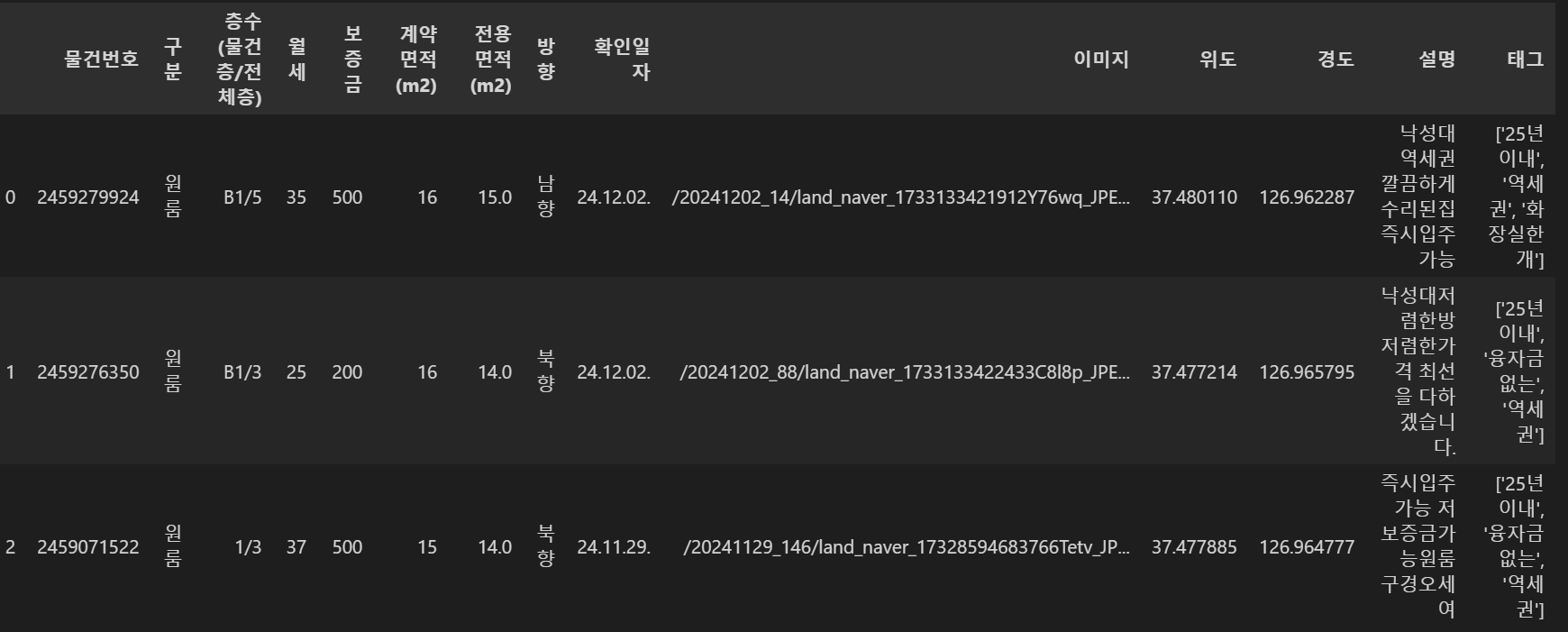
data.info()
데이터는 총 1860개이며 보증금, 이미지, 설명에는 일부 결측값이 존재합니다.
이미지와 설명 변수는 설정한 조건에 해당하지 않으니 상관없지만 보증금 컬럼의 경우 중요 조건이기 때문에 조치를 취해주겠습니다.
① 보증금 컬럼 처리
# 결측값 제외
data = data.dropna(subset=['보증금'])
data['보증금'].unique()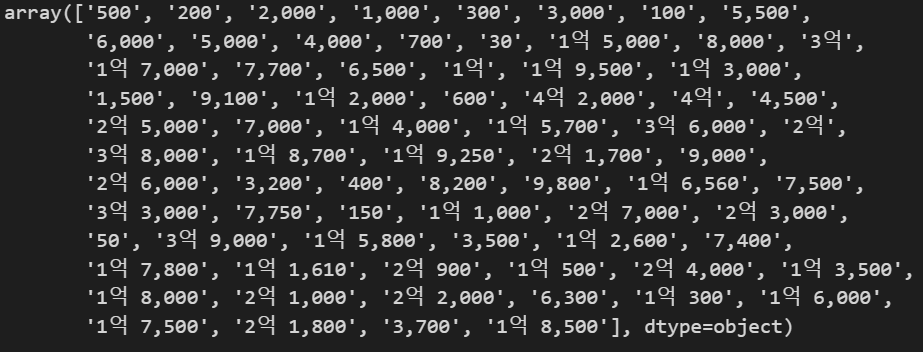
보증금의 고유값을 보니 문자열 타입이며 2,000 , 1억 1,000 이런 식으로 숫자와 한글이 동시에 사용되고 있습니다.
이를 하나의 타입으로 변경하겠습니다.
data = data.query('~보증금.str.contains("억")')
# 숫자 변환 -> ,제거후 타입 변환
data['보증금'] = data['보증금'].str.replace(',', '').astype('int')
data['보증금'].unique()
저희가 설정한 조건은 보증금 3000만 원 이하이기 때문에 억 단위는 관심 대상이 아닙니다.
그렇기 때문에 우선 '억'이 들어간 행을 제거해 주었습니다.
그 후, 숫자 타입으로 변경하기 위해 replace 함수를 사용하여 ,를 공백으로 치환하는 작업을 거쳤습니다.
② 층수 컬럼 처리
설정한 세부 조건 중 지하, 반지하, 꼭대기층은 선호하지 않는다는 조건을 맞추기 위해 층수 컬럼에 대한 처리를 진행하겠습니다.
원 데이터에서는 6/8 , B1/4 이런 식으로 물건층/전체층이 동시에 표시되어 있습니다.
분석의 용이를 위해 물건층과 전체층 분리 후, 비선호층에 대한 유무를 판단하겠습니다.
data[['물건층', '전체층']] = data['층수(물건층/전체층)'].str.split('/', expand= True)
# expand= True 조건이 없다면 리스트 형태로 들어가게 됨
split 함수를 사용하여 / 를 기준을 물건층과 전체층을 분리했습니다.
data['물건층'].unique()
물건층에 대해 고유값을 구해보면 층수와 저-중-고 형태로 구성되어 있는 걸 확인할 수 있습니다.
저-중-고에 대해 따로 처리를 하진 않고, 피할 조건인 지하, 1층, 꼭대기층에 대한 여부를 파악해 보겠습니다.
# 비선호층 여부 컬럼 생성
def floor_info(target, total):
try:
if target in ['B1', 'B2']: #지하이면
return 'y'
elif int(target) == 1 or int(target)/int(total) == 1: #1층이거나 꼭대기층이면
return 'y'
else:
return 'n'
except ValueError: # 저층, 중층, 고층 표현
return 'n'
data['비선호여부'] = data.apply(lambda x: floor_info(x['물건층'], x['전체층']), axis = 1)
data.head(1)
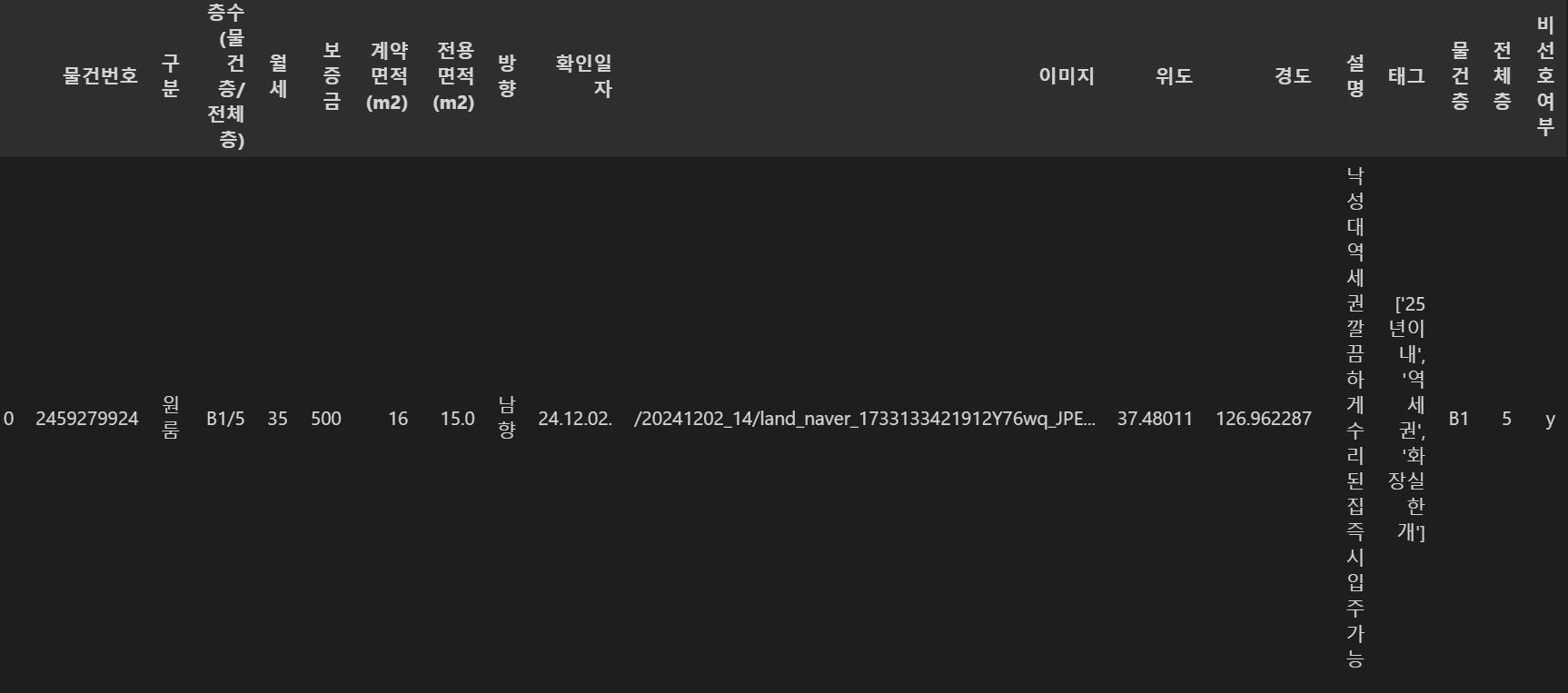
비선호여부 컬럼을 생성하여 yes or no로 나타냈습니다.
여기서 꼭대기층은 물건층 == 전체층이므로, 두 층을 나눴을 때 1이나 오는 것을 조건으로 설정했습니다.
③ 보증금, 층수, 북향에 관한 필터링
필터링을 하기 전, 방향 컬럼의 고유값을 먼저 보겠습니다.
data['방향'].unique()
총 8개의 고유값으로 구성되어 있고
저희는 북향을 선호하지 않는다는 조건이 있으니, '북'이 들어가는 행을 제거할 필요가 있습니다.
또한 저희는 ①, ②에서 보증금과 층수에 관한 처리를 해 놨습니다.
이제 설정한 세부 조건에 맞춰 일차 필터링을 진행하겠습니다.
data_filtered = data.query('300 <= 보증금 <= 3000 and 비선호여부 == "n" and 전체층 != "1" and ~방향.str.contains("북")')
data_filtered #784개
그럼 정해진 조건 중 우선 3개의 조건을 만족하는 데이터는 784개로 나타났습니다.
- 보증금 3000만 원 이하 ✅
- 월세는 저렴할수록 좋음
- 지하, 반지하, 꼭대기층은 선호하지 않음 ✅
- 전용면적이 클수록 좋음
- 북향은 선호하지 않음 ✅
- 연식이 오래되지 않을수록 좋음
- 지하철역에서 가까울수록 좋음
④ 연식 정보 파악
이제 연식정보에 대해 파악해 보겠습니다.
원 데이터에서 연식 정보를 포함하고 있는 것은 태그 컬럼입니다.
data_filtered['태그'].sample(10)
태그는 최대 4개로 구성되며, 첫 번째 요소에 연식 정보를 담고 있습니다.
연식에 대해 효과적으로 다루기 위해, 태그 컬럼을 총 4개의 요소로 구분해서 다루겠습니다.
data_filtered[['tag1', 'tag2', 'tag3', 'tag4']] = data_filtered['태그'].str.replace('[\[\]]', '').str.split(',', expand=True)
replace 함수를 통해 양 옆의 괄호를 공백으로 바꾼 후 split 함수를 이용해 ,를 기준으로 tag1,2,3,4로 분리했습니다.
data_filtered = data_filtered.query('tag1.str.contains("년")') # 연식 정보가 있는 데이터만 필터링
query 함수를 이용하여 데이터에서 '년'이라는 단어가 있는 데이터만 필터링합니다.
data_filtered['tag1'].head()
tag1을 보면 숫자와 문자가 함께 쓰인 문자열입니다.
여기서 저희가 사용할 건 '년' 앞에 숫자만 있는 데이터이므로 추가 작업이 필요합니다.
import re
result = []
for tag in data_filtered['tag1']:
first_element = tag.split('년')[0]
number = re.findall(r'\d+', first_element) #숫자만 찾기
result.append(number)
data_filtered['연식'] = result
data_filtered['연식'] = data_filtered['연식'].astype(str).str.strip('[]').str.strip(" ' ") # 괄호 제거, ' 제거
data_filtered['연식'].head()
data_filtered['연식'].unique()
잘 분리가 되었는지 unique를 통해 살펴봤습니다.
# 숫자 타입으로 변환
data_filtered['연식'] = pd.to_numeric(data_filtered['연식'], errors='coerce')
이제 마지막으로 문자열인 연식 컬럼을 숫자형으로 바꿔줍니다.
또한 설정한 세부 조건을 비교하기 위해 필요한 컬럼만 남깁니다.
# 필요 컬럼만 남기기
data_filtered = data_filtered[['물건번호','월세','보증금','전용면적(m2)','방향','위도','경도','물건층','전체층','연식']]
data_filtered.head()
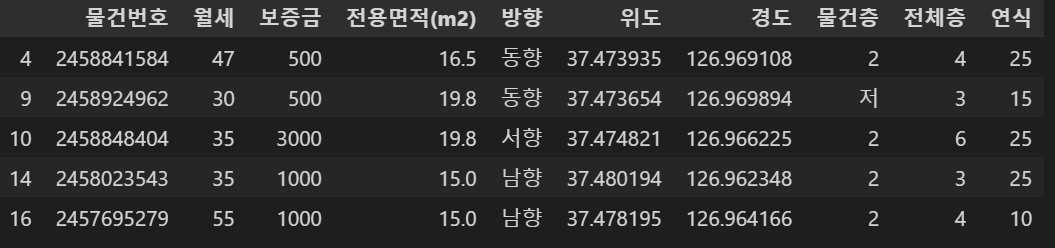
⑤ 위도, 경도 정보를 이용하여 역까지의 거리 계산
이제 지하철역에서 가까울수록 좋다는 조건을 판단하기 위해 서울시 역사마스터 정보 데이터를 통해 관악구 근처 역과 매물 사이의 거리 계산을 해보겠습니다. 여기서 계산의 편의를 위해 2호선을 기준으로 역간 거리를 구하였습니다.
우선 서울시 역사마스터 정보 데이터셋을 살펴보겠습니다.
coordinate = pd.read_csv('서울시 역사마스터 정보.csv', encoding='cp949')
coordinate.head()

데이터셋에는 역사ID, 역사명, 호선, 위도, 경도 정보가 담겨있습니다.
저희는 앞에서 2호선을 기준으로 설정했으니
호선을 2호선으로 고정하고, 관악구 근처 지하철역을 staton_list에 담아 해당 역사명의 정보만 가져오겠습니다.
coordinate = coordinate.query('호선 == "2호선"')
station_list = ['신대방', '신림', '봉천', '서울대입구(관악구청)', '낙성대', '사당']
coordinate= coordinate.query('역사명 in @station_list')
위경도 거리를 재기 위해선 haversine이라는 라이브러리를 이용하게 됩니다.
# 위경도 거리 재는 라이브러리
# pip install haversine
from haversine import haversine
# 예시 (계산하고 싶은 곳, 기준, 계산 단위) -> 직선거리가 계산됨
haversine((37.487462,126.913149), (37.484201,126.929715), unit = 'm')
haversine의 원리는 계산하고 싶은 곳의 위경도 정보와 기준이 되는 곳의 위경도 정보를 입력하고 계산 단위 'm' or 'km' 등을 설정하면 두 공간 사이의 직선거리가 계산이 되는 구조입니다. 이를 이용해서 각 매물과 역간 거리를 계산해 보겠습니다.
# 매물 별 역간 거리 계산하는 함수 생성
def distance(station_name, lat, long):
station_lat = coordinate.query(f'역사명 == "{station_name}"')['위도'].values[0]
station_long = coordinate.query(f'역사명 == "{station_name}"')['경도'].values[0]
distance = haversine((station_lat,station_long), (lat, long), unit= 'm' )
return distance
# i는 역사명이 됨
for i in station_list:
data_filtered[i] = data_filtered.apply(lambda x: distance(i, x['위도'], x['경도']), axis= 1)
data_filtered.head(5)
매물과 6개의 역 간의 거리를 구했습니다.
저희가 필요한 건 매물과 가장 가까운 특정역이 어디인지에 대한 정보이기 때문에 최소거리를 구한 후, 최소거리 컬럼만 남기겠습니다.
# 역까지의 최소 거리
data_filtered['역까지최소거리'] = data_filtered.apply(lambda x: min([x['신대방'], x['신림'], x['봉천'], x['서울대입구(관악구청)'], x['낙성대'], x['사당']]), axis= 1)
# 역까지의 최소거리 컬러만 남김
data_filtered.drop(station_list, axis= 1, inplace=True)
data_filtered.head()
여기까지가 최적의 자취방을 구하기 위한 전처리 단계입니다.
4. 분석
① 분포 확인
우선 각 컬럼에 대한 분포를 확인해 보겠습니다.
# 분포 확인
for x in ['월세', '보증금', '전용면적(m2)', '연식', '역까지최소거리']:
fig = px.box(data_frame= data_filtered, x=x, width=500, height= 300)
fig.show()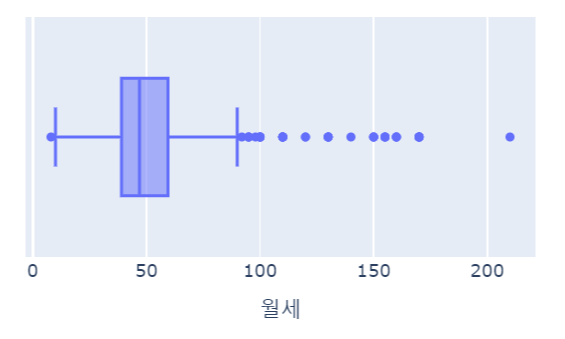
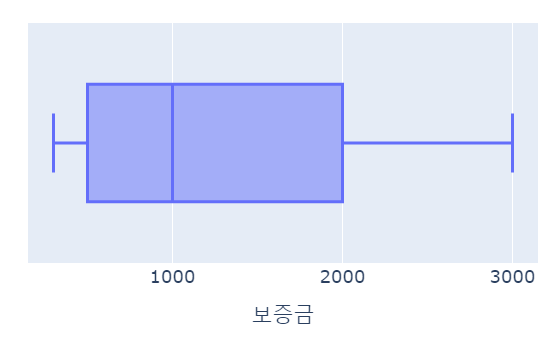


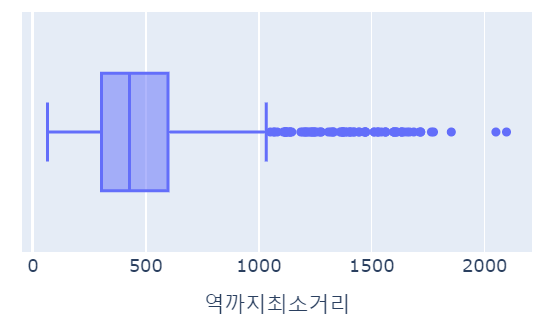
| Q1 | median | Q3 | |
| 월세 | 39 | 47 | 59.5 |
| 보증금 | 300 | 1000 | 2000 |
| 전용면적(m2) | 18.1 | 19.83 | 23.1 |
| 연식 | 10 | 15 | 25 |
| 역까지최소거리 | 303 | 427 | 597 |
② 월세, 전용면적, 연식, 지하철 역까지의 거리 점수 매기기
설정한 조건 7가지 중 보증금, 층수, 북향의 정보는 위에서 필터링해 놨습니다.
나머지 4가지의 조건은 점수를 매겨 분석을 진행하겠습니다.
qcut 함수를 이용하면 등급을 쉽게 매길 수 있습니다. 5개의 등급으로 구분하겠습니다.
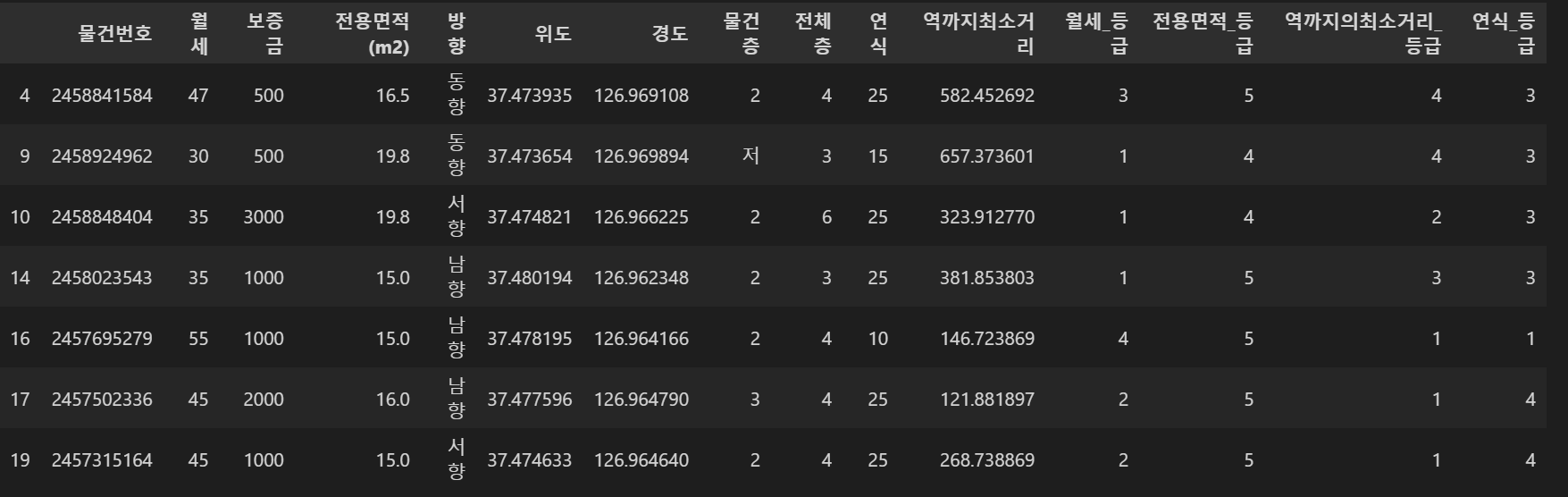
data_filtered['월세_등급'] = pd.qcut(data_filtered['월세'], 5, labels=[1,2,3,4,5]) # 월세가 작을수록 1등급
data_filtered['전용면적_등급'] = pd.qcut(data_filtered['전용면적(m2)'], 5, labels=[5,4,3,2,1]) # 면적이 클수록 1등급
data_filtered['역까지의최소거리_등급'] = pd.qcut(data_filtered['역까지최소거리'], 5, labels=[1,2,3,4,5]) #거리가 가까울 수록 1등급
data_filtered['연식_등급'] = pd.qcut(data_filtered['연식'].rank(method='first'), 5, labels=[1,2,3,4,5]) # 연식이 낮을수록 1등급
# 연식의 경우 중복값이 많기 때문에 중간에 값을 자르기 어려움 -> rank 함수를 추가해서 임의로 등수를 매겨서 등급을 잘라달라는 내용 추가
월세, 역까지의 최소거리, 연식 컬럼의 경우 값이 클수록 낮은 등급인 1에 가깝고 값이 작을수록 높은 등급인 5에 가깝게 됩니다. 반면 면적의 경우 클수록 좋은 것이기 때문에 값이 클수록 1등급에 가까운 것으로 설정했습니다.
③ 시각화
매겨진 등급을 가지고 최종 필터링을 진행해 보겠습니다.
제가 사용한 기준은 다음과 같습니다.
월세 50만 원 이하(3등급 이하), 면적 넓은 거 선호 (2등급 이상), 연식 10년 이하(2등급 이하), 거리 가까운 것 선호(2등급 이하)
#임의 기준으로 최종 필터링
data_filtered_final = data_filtered.query('월세_등급 <= 3 and 전용면적_등급 >= 2 and 연식_등급 <= 2 and 역까지의최소거리_등급 <= 2')
data_filtered_final #17개
조건에 맞는 매물은 총 17개입니다.
이를 시각화해 보겠습니다.
# 17개 매물 시각화
f=folium.Figure(width=700, height=500)
m=folium.Map(location=[37.486313, 126.935378], zoom_start=14).add_to(f)
for idx in data_filtered_final.index:
lat = data_filtered_final.loc[idx,'위도']
long=data_filtered_final.loc[idx,'경도']
num=data_filtered_final.loc[idx,'물건번호']
folium.Marker([lat, long]
, popup=f"<a href=https://m.land.naver.com/article/info/{num}>링크</a>"
).add_to(m)
m

이것으로 부동산 데이터를 활용한 최적의 자취방 구하기 프로젝트가 끝났습니다.
지금까지 읽어주셔서 감사합니다:)
'데이터 분석 > 프로젝트' 카테고리의 다른 글
| [Python] 부동산 데이터를 활용한 최적의 자취방 구하기(1) (0) | 2024.12.27 |
|---|---|
| [Python] 사용자 행동 로그 데이터를 활용한 퍼널 분석 (6) | 2024.10.02 |
| [Python] 유통 데이터를 활용한 리텐션과 RFM 분석(4) (2) | 2024.08.25 |
| [Python] 유통 데이터를 활용한 리텐션과 RFM 분석(3) (0) | 2024.08.01 |
| [Python] 유통 데이터를 활용한 리텐션과 RFM 분석(2) (0) | 2024.07.21 |



