크롤링(Crawling)은 웹에서 자동으로 데이터를 수집하는 기술을 말합니다.
이번 프로젝트에서는 크롤링을 통해 부동산 데이터를 수집하고, 이를 활용하여 조건에 맞는 자취방을 구하는 것을 진행해 보겠습니다.
1. 데이터 소개 및 수집
분석에 사용한 데이터는 네이버 부동산에서 서울시 관악구에 있는 월세 형태의 오피스텔 ·빌라 ·원룸 형태의 매물들입니다.
데이터는 네이버 부동산 모바일 버전 (https://fin.land.naver.com/?content=recent)을 통해 수집하겠습니다.
[크롤링 대상 데이터]
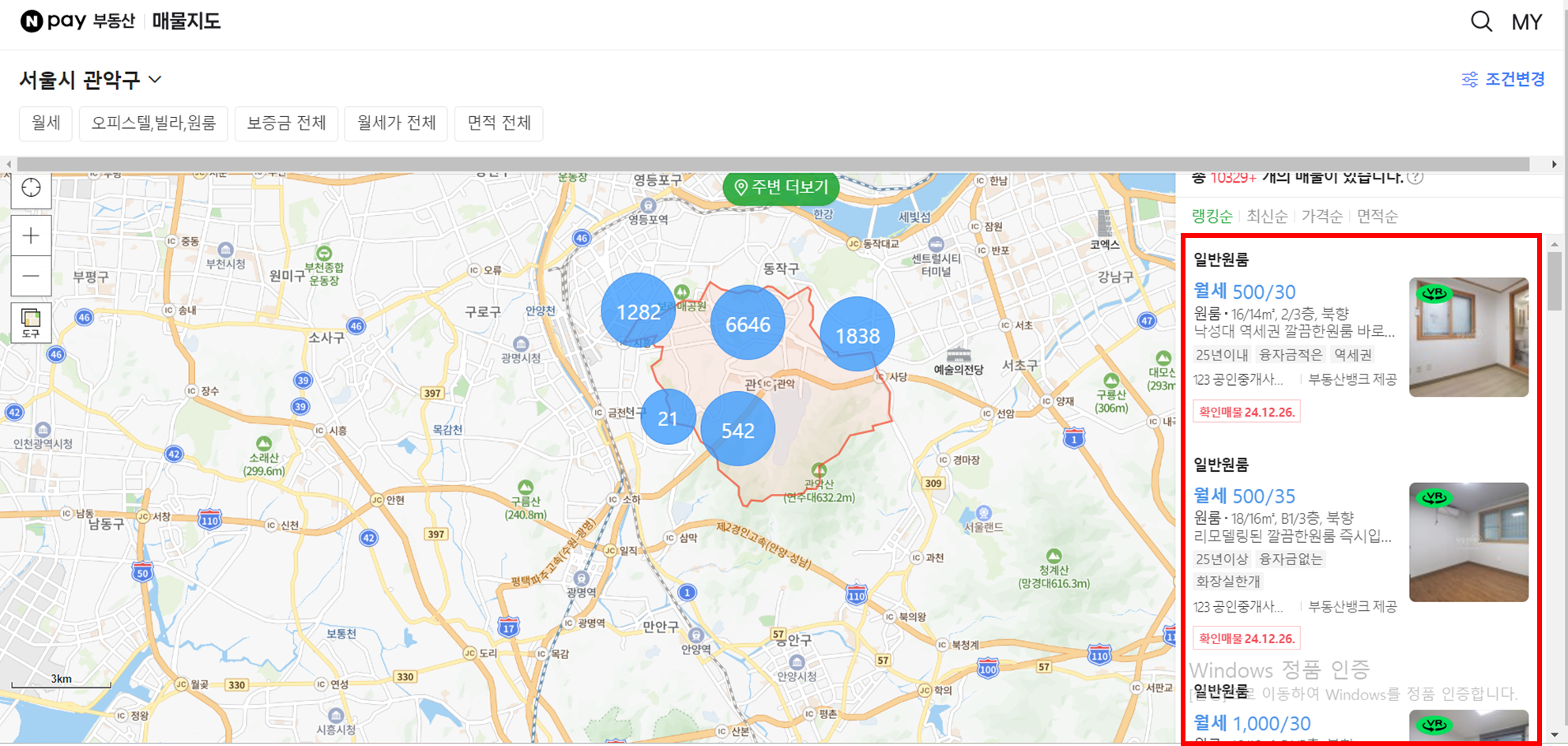
저희에게 필요한 데이터는 페이지 오른쪽에 위치한 빨간 박스 안의 매물 정보입니다.
1) URL 분석
영상과 같이 개발자 도구 - 도구 더보기에 들어가 network를 누른 후, 매물들을 스크롤해 보면 aiticleList가 생성되는 것을 확인할 수 있습니다.
생성된 aiticleList 중 하나를 클릭해 보면 Request URL 정보를 알 수 있고,
이를 복사해서 검색을 해 보면, (글자가 너무 작아 사진상으론 잘 안 보이지만) 층수, 가격, 방향, 전용면적 등에 대한 정보가 담겨 있습니다.

또한, 스크롤을 할 수록 aiticleList가 그만큼 생성되는데, 안의 내용을 보면 page가 하나씩 증가하는 것을 발견할 수 있습니다. 즉, 스크롤을 할수록 페이지가 증가하면서 매물 정보들을 받아오는 형태라 할 수 있습니다.
따라서, for문을 사용하여 페이지를 순차적으로 증가시키며 Request URL 에 있는 정보들을 가져오는 과정이 필요합니다.
2) 단일 URL에서 데이터 가져오기
우선 하나의 URL에서 정보를 가져와 보겠습니다.
from user_agent import generate_user_agent, generate_navigator
user_agent = generate_user_agent()
user_agent
import requests
import numpy as np
import pandas as pd
from tqdm import tqdm
import time
#크롤링
# 크롤링
url = 'https://m.land.naver.com/cluster/ajax/articleList?itemId=&mapKey=&lgeo=&showR0=&rletTpCd=OPST%3AVL%3AOR&tradTpCd=B2&z=12&lat=37.481021&lon=126.951601&btm=37.390378&lft=126.7845745&top=37.5715542&rgt=127.1186275&totCnt=10109&cortarNo=1162000000&sort=rank&page=2'
user_agent = generate_user_agent()
headers = {'User-Agent' : user_agent}
headers
requests.get을 통해 데이터를 가져오겠습니다.
res = requests.get(url, headers= headers)
res.json() # 데이터 가져오기

json 결과를 보면 실직적으로 필요한 내용이 'body'라는 key값 안에 리스트 형태로 들어있는 것을 알 수 있습니다.
여기까지가 URL 하나에서 데이터를 가져오는데 필요한 단계입니다.
이제 이를 for문을 통해 하나로 만들어보겠습니다.
3) 반복문으로 모든 페이지 크롤링
# 반복문을 통해 100페이지 까지의 매물 정보 가져오기
article_list = []
for i in tqdm(range(1, 101)):
try: #페이지가 100까지 없는 경우가 있으니, try - except 구문 사용
url = f'https://m.land.naver.com/cluster/ajax/articleList?itemId=&mapKey=&lgeo=&showR0=&rletTpCd=OPST%3AVL%3AOR&tradTpCd=B2&z=12&lat=37.481021&lon=126.951601&btm=37.390378&lft=126.7845745&top=37.5715542&rgt=127.1186275&totCnt=10109&cortarNo=1162000000&sort=rank&page={i}'
user_agent = generate_user_agent()
headers = {'User-Agent' : user_agent}
res = requests.get(url, headers= headers)
time.sleep(0.01) # 서비스의 부하를 막기 위해 request.get을 시간을 두고 하라는 내용
article_json = res.json()
article_body = res.json()['body']
article_list.append(article_body)
except:
break
4) 리스트 구조 풀어주기
크롤링된 article_list는 리스트 안에 또 다른 리스트 형태로 구성되어 있습니다.
article_list[0] #리스트 안에 리스트 구조
저희가 원하는 건, 하나의 리스트에는 하나의 매물 정보만 있는 것이기 때문이 이를 풀어주는 작업을 하겠습니다.
article_list1 = [j for i in article_list for j in i]
5) 데이터 변환 및 저장
사용하기 편하게 dataframe 형태로 바꿔주겠습니다.
# df 형태로 변경
data = pd.DataFrame(article_list1)
data
원 데이터의 경우 총 51개의 컬럼으로 구성되어 있지만,
저희는 전부 필요한게 아니기 때문에 필요한 컬럼만 남기고 rename을 해 주었습니다.
data = data[['atclNo','rletTpNm','flrInfo','rentPrc','hanPrc','spc1','spc2','direction','atclCfmYmd','repImgUrl','lat','lng','atclFetrDesc','tagList']]
data.columns = ['물건번호','구분','층수(물건층/전체층)','월세','보증금','계약면적(m2)','전용면적(m2)','방향','확인일자','이미지','위도','경도','설명','태그']
data
이제 데이터를 저장하면 데이터 수집 단계가 마무리됩니다.
# 엑셀로 저장
data.to_excel('부동산데이터.xlsx', index= False)
이것으로 크롤링을 활용한 데이터 수집 단계가 완료되었습니다.
내용이 길어지는 관계로 분석 내용은 다음 포스팅에 이어서 작성하겠습니다.
지금까지 읽어주셔서 감사합니다:)
'데이터 분석 > 프로젝트' 카테고리의 다른 글
| [Python] 부동산 데이터를 활용한 최적의 자취방 구하기(2) (2) | 2024.12.27 |
|---|---|
| [Python] 사용자 행동 로그 데이터를 활용한 퍼널 분석 (5) | 2024.10.02 |
| [Python] 유통 데이터를 활용한 리텐션과 RFM 분석(4) (0) | 2024.08.25 |
| [Python] 유통 데이터를 활용한 리텐션과 RFM 분석(3) (0) | 2024.08.01 |
| [Python] 유통 데이터를 활용한 리텐션과 RFM 분석(2) (0) | 2024.07.21 |



